
Background
Large language models continue to scale in size, capability, and resources required to run them. Inference efficiency (latency, throughput, and memory footprint) has therefore become a first-order concern for deploying these models in practice. This is especially true in resource-constrained environments, like on-premises deployments, where GPU budgets are fixed and efficiency determines how much intelligence can be packed onto each device.
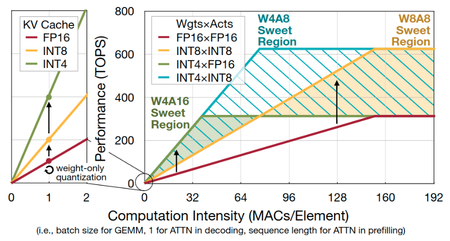
Model quantization is one key lever for improving efficiency. We can quantize one or more of [Weights, Activations] to lower precision and denote this by WxAy. Two commonly used quantization schemes on NVIDIA Hopper GPU Architecture are W4A16 and W8A8; each has its pros and cons:
Ideally, we would like to combine the low memory footprint of W4 with the high compute throughput of A8. Hence W4A8, which allows us to be performant in both memory-bound (decoding) and compute-bound (prefill) regimes:
We’re excited to share our work on production ready W4A8 dense and grouped GEMM kernels targeting Hopper architecture, with integration in vLLM for dense and Mixture of Experts (MoE) models. Our W4A8 kernels achieve up to 58% Time to First Token and 45% Time Per Output Token speed up compared to W4A16, with improvements scaling consistently across batch sizes.
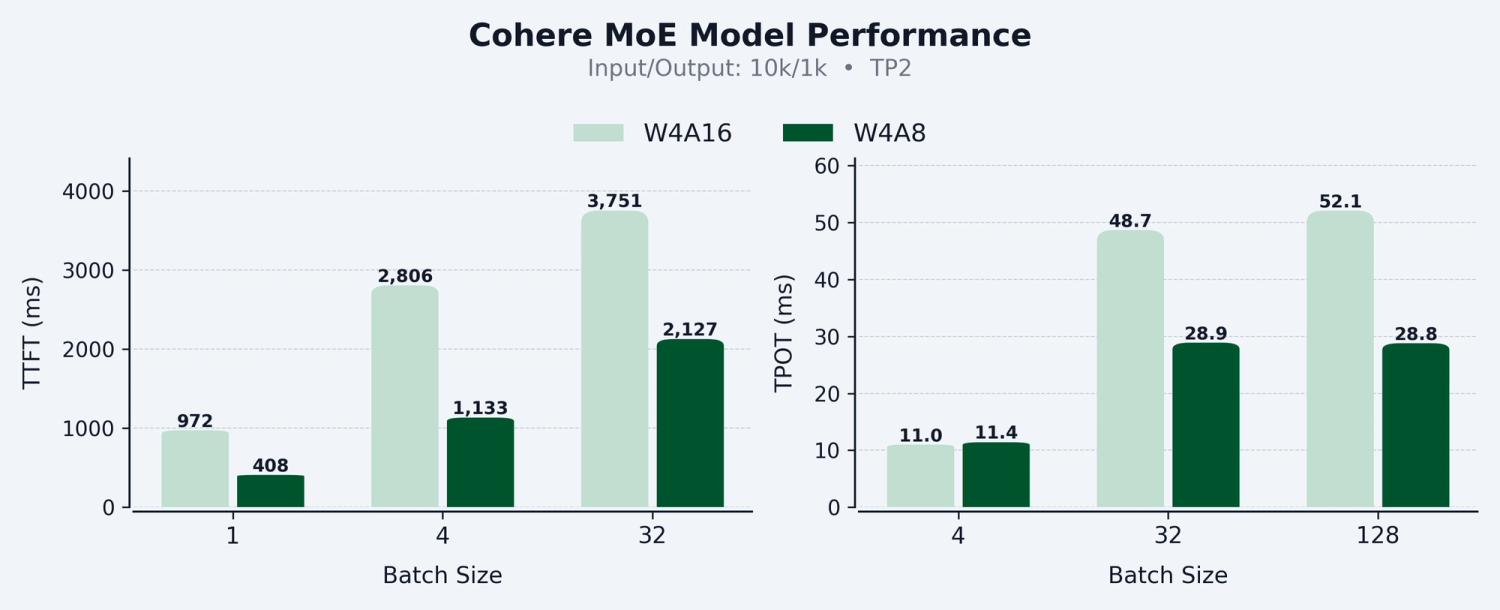
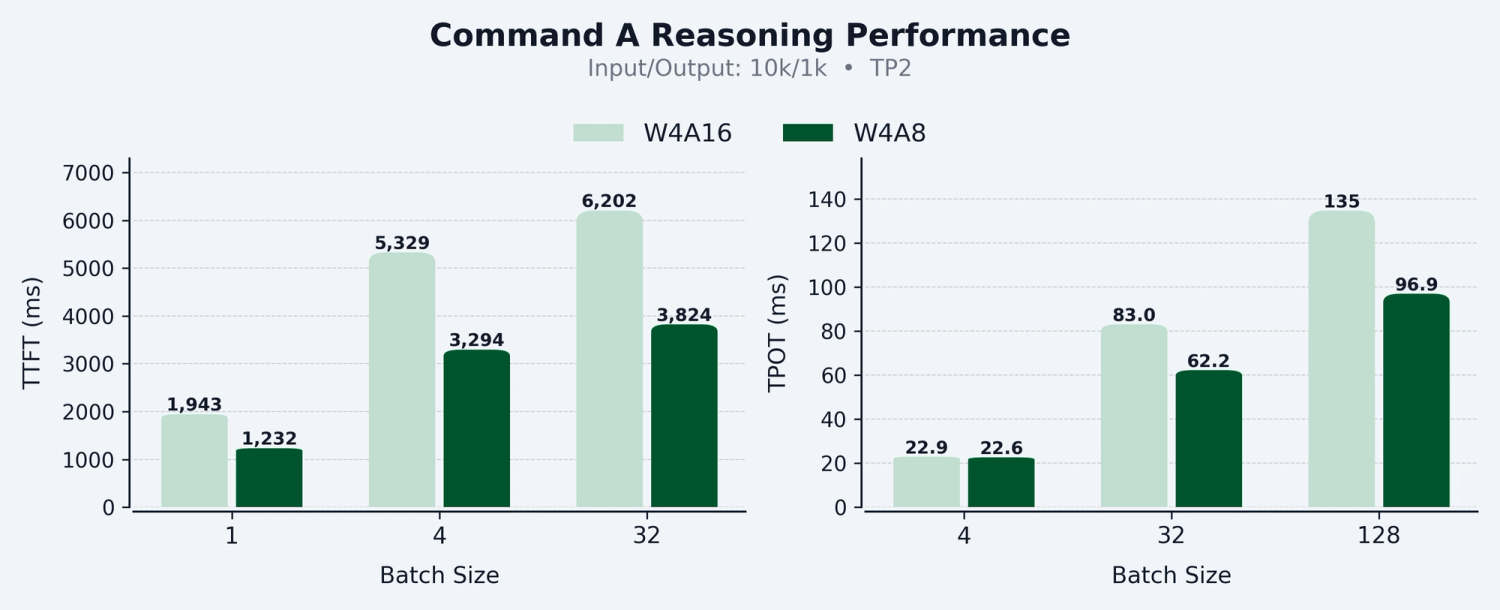
Read on as we dive into the implementation details, the quantization recipe, and the key challenges we encountered.
Implementation
This section covers the key design choices behind our W4A8 kernels: how we optimized for latency and how we preserved model quality at lower precision.
High-Performance W4A8 GEMM Kernel
For W4A8, the weight precision (INT4) is different from the activation precision (FP8). However, Hopper Tensor Core (wgmma) instructions expect both operands to have the same precision; this means we need to convert the lower precision operand (INT4 weights) to the activation precision (FP8/BF16) before running the final matrix multiply in the higher precision. For W4A16, this process roughly follows the steps:
Load INT4 weights and BF16 group scales from HBM into registers
Dequantize INT4 weights to BF16 using NVIDIA CUDA cores
Run the matrix multiplication in BF16 precision using Tensor Cores.
By pipelining these steps properly, we can effectively hide the overhead of dequantization and achieve near peak BF16 FLOPs. We refer readers to these two excellent resources for more details on how this is done on Hopper.
With W4A8, naïvely using this approach leads to two main issues:
FP8 Tensor Core throughput is roughly ~2x BF16/FP16 so there is less room to hide dequantization ops
CUDA cores don’t natively support FP8 scalar math, so in practice we need to convert to BF16/FP16, do the math, then convert back to FP8.
As a result this approach is bottlenecked on dequantization and is not able to achieve peak FP8 FLOPs. Fortunately, CUTLASS offers a lookup-table (LUT) based solution to this problem. Instead of using scalar math to directly convert INT4 weights to FP8, use a LUT:
For each FP8 scale value
s, there are only 16 possible values ofs * wwherewis an INT4 valuePrecompute eight of them as a pre-processing step (once, on initial model load)
Inside the GEMM mainloop:
For each FP8 scale value construct a lookup table which directly maps from the INT4 value
wtos * wWhen dequantizing, use this LUT instead of doing scalar math
The figure below quantifies the performance improvement from using the LUT approach.
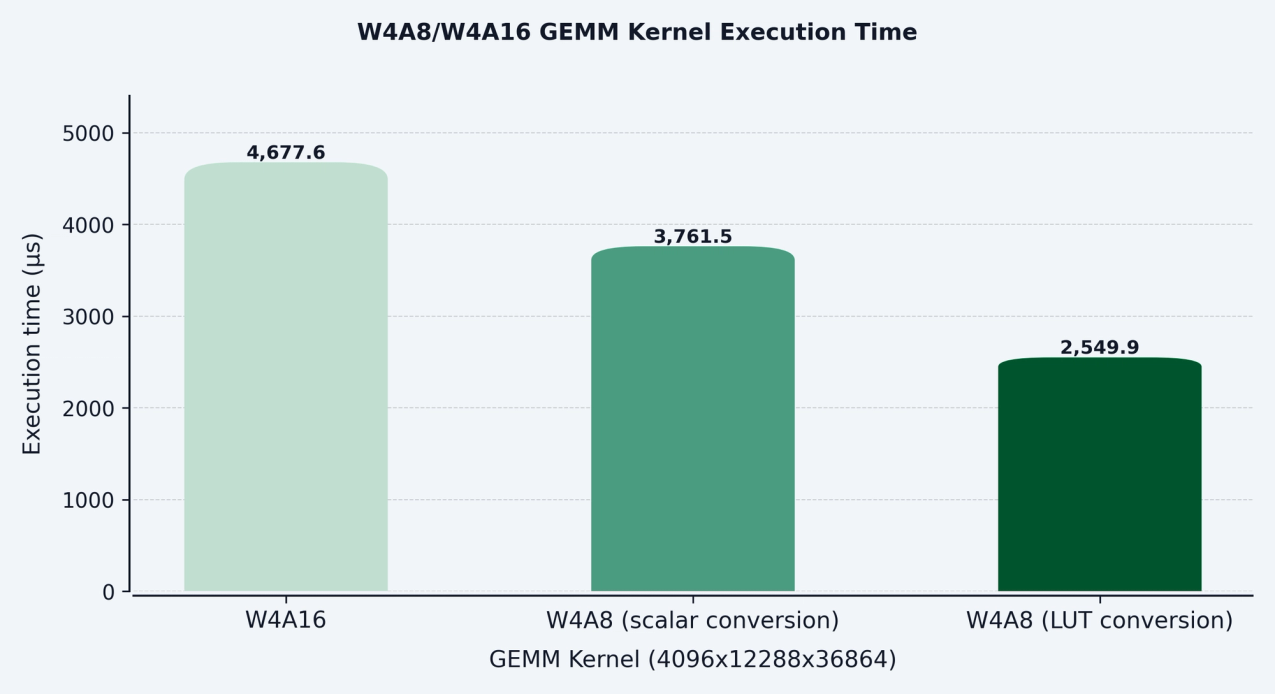
The LUT-based solution requires a specific weight encoding and layout. We noticed the existing pre-processing code was quite slow for large models (often taking >10min at startup) so we implemented a custom CUDA kernel to significantly speed it up.
Accurate W4A8 Kernel
The most straightforward way to produce a W4A8 checkpoint for a model is
Use an existing 4-bit quant method (e.g. AWQ, GPTQ) to produce a W4A16 checkpoint
Cast the group scales from BF16/FP16 → FP8
While this produced a reasonable model, we observed that naïvely doing (2) lead to statistically significant quality drops on knowledge-intensive evals like MMLU-Pro. Inspecting the distribution of group scales provided some insight:
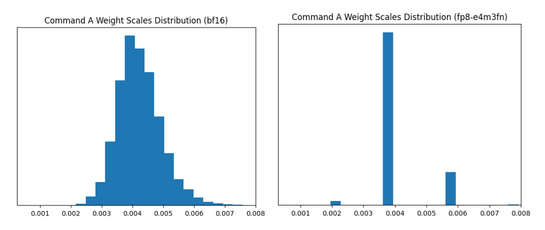
Because of the lower precision of FP8, there were only four unique values represented in the scales after casting (with the majority mapped to only one value) which leads to bad quantization granularity.
To achieve better quantization granularity, we can quantize each column of BF16 group-wise scales to FP8: fp8_scales, channel_scales = quant_fp8(bf16_scales) where channel_scales is in FP32. Note that this is the same operation applied to dynamically quantize token activations to FP8 during inference; here we also apply it to the group scales themselves. In the GEMM epilogue, we apply both the per-token and per-channel FP32 scales (also known as outer vector scaling). This operation is basically free from a computational perspective, and vLLM has a nice abstraction to easily add this type of epilogue to different GEMM/grouped GEMM implementations.
There is one more issue to address: after multiplying the quantized FP8 scales by INT4 weights, a large portion of the resulting values exceed FP8 (E4M3) range and are therefore clamped to [FP8_MIN, FP8_MAX], as shown in the figure below.
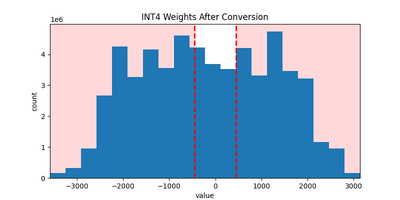
To fix this issue, we manually scale the FP8 scales by 1/8 (so that weights are guaranteed to be in FP8 range after multiplication by INT4 values) and compensate by multiplying per-channel scales by eight so that the overall math is correct. This way, we can represent the full weight range without clipping.
The overall W4A8 GEMM process is summarized below:
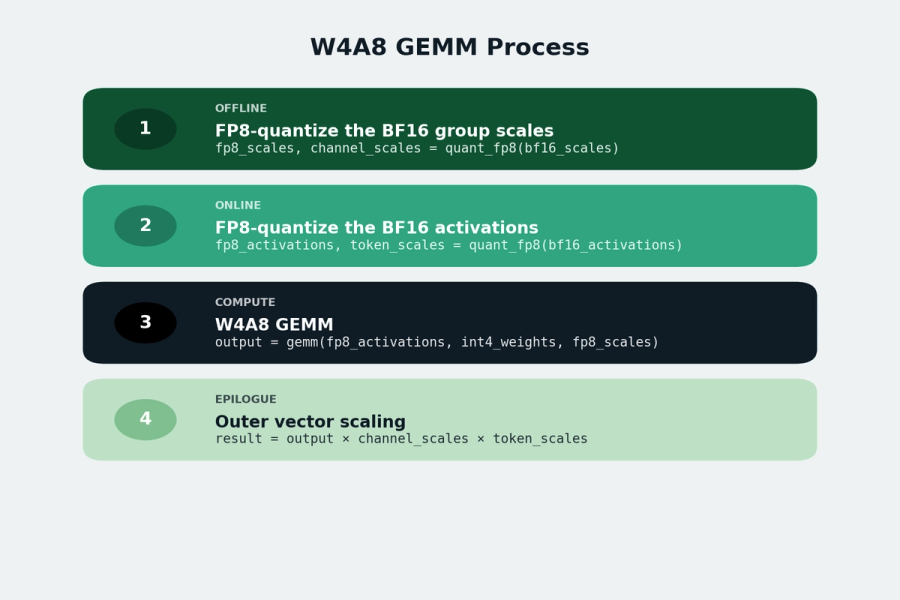
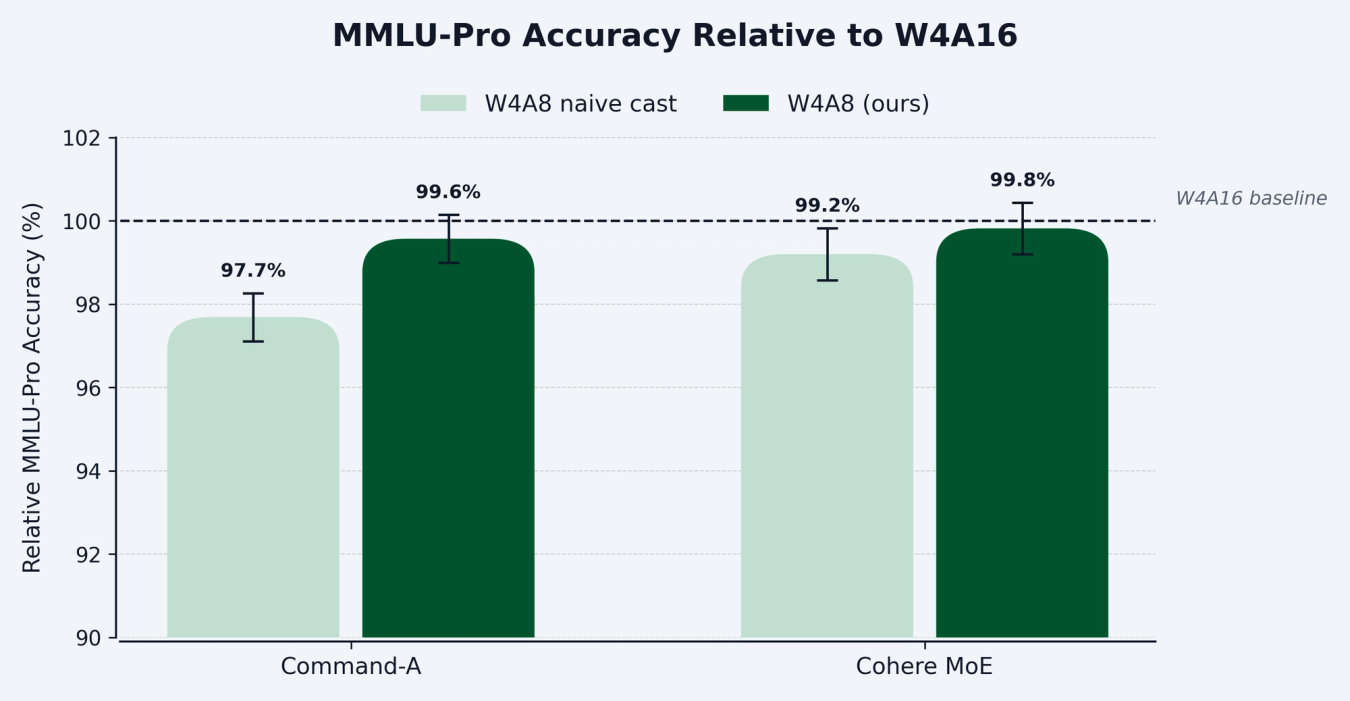
With these changes, we were able to restore model quality to the original W4A16 baseline. The figure below shows the relative MMLU-Pro accuracy of Cohere MoE and Command A quantized to W4A8 using naïve FP8 casting versus our approach. Our proposed method recovers more than 99.5% of the W4A16 accuracy for both models, consistently outperforming naive FP8 casting.
Quantization recipe
North is Cohere’s enterprise AI platform for building secure, production-grade AI agents. Models deployed in North must handle long-horizon, agentic workflows with heavy tool use, not just short, single-turn chat. After quantization, the model needs to preserve this behavior.
We began by applying AWQ to quantize the model to W4A16. However, we found that applying AWQ with standard calibration settings, such as UltraChat200K with maximum sequence length 2,000, led to noticeable quality regressions in North. By analyzing failure cases, we found that most errors occur on agentic tasks that require long context, often well beyond 20,000 tokens. This suggests that short-context calibration data is not representative of real production usage.
To address this, we switched to internal agentic traces for calibration, with sequence lengths ranging from 1,000 up to 64,000. These traces contained long instruction chains, multi-step reasoning, and tool invocations that more closely matched how the model is used in practice. However, even with this improved dataset, the initial quantization results were still unsatisfactory.
We looked more closely at the calibration data and it revealed the issue: a large fraction of tokens came from chat templates and tool descriptions, which were long and highly repetitive. Since AWQ relies on mean activation magnitude to guide its optimization, these repetitive hidden states dominated the statistics. This strongly biases the calibration process, effectively shrinking the useful optimization space and leading to poor quantization decisions.
To address this issue, we added token masking support to AWQ in llm-compressor. Token masking allowed us to exclude non-informative tokens from calibration statistics while still calibrating on the same long-context traces such as:
System prompts
Templates
Tool descriptions
With token masking enabled, we were able to generate production-ready W4A16 models that met our internal quality standards and preserved agentic performance in North. We believe the capability of token masking is broadly useful beyond our setting and is currently missing from many existing quantization libraries. As system prompts continue to grow in length, their impact on calibration becomes increasingly significant. For example, tools such as Claude Code are known to use system prompts that exceed 20,000 tokens, making token-level control during calibration essential rather than optional.
We are also exploring INT4A8 quantization-aware distillation (QAD) as a complementary path to improve quality. The key idea is that post-training quantization alone cannot fully correct for the mismatch introduced by low-precision weights and activations, since the model was never optimized under those constraints. With QAD, we train a quantized student to match the output distribution of a higher-precision teacher under the INT4A8 quantization setup. Concretely, we use a standard distillation loss of the form:
L = KL (softmax(z_t)||softmax(z_s))
In this case, zt and zs are the teacher and student logits. We also construct a targeted data mix from the original SFT training dataset based on the quality drop observed after PTQ. If PTQ hurts performance more strongly in a particular capability area, we treat that as a signal that this domain is harder to preserve under quantization, and allocate more distillation data to it. In this way, QAD complements calibration by directly adapting the model to quantization noise while placing more emphasis on the capabilities that degrade the most under PTQ.
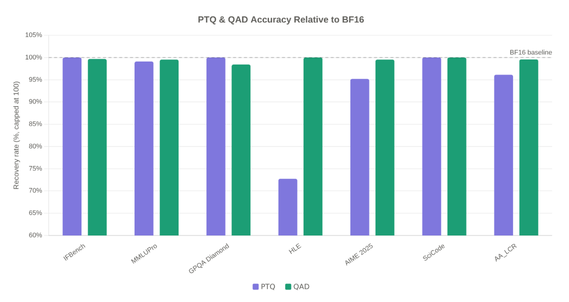
The figure below shows the accuracy recovery of our PTQ and QAD techniques on an internal W4A8 quantized MoE model. AWQ with token masking achieves strong recovery on most tasks, while QAD further closes the gap, reaching competitive quality with the unquantized BF16 baseline.
Conclusion
Our proposed W4A8 quantization approach achieves a sweet spot for LLM inference, combining the memory efficiency of 4-bit weights with the compute throughput of 8-bit activations. Our Hopper-optimized GEMM kernels, now integrated in vLLM, demonstrate that these gains are practical and production-ready, delivering up to 58% faster prefill and 45% faster decoding compared to W4A16, while having competitive quality with the unquantized BF16 baseline.
Acknowledgements
On the Cohere side, thank you to Acyr Locatelli and Bharat Venkitesh for providing technical support throughout this work. We extend a special thanks to members of the Red Hat team: Michael Goin, Dipika Sikka, Lucas Wilkinson, Kyle Sayer, Brian Dellabetta, and Charles Hernandez. We appreciate their collaboration and contributions within the vLLM community.
Ready to build your next project? Login or create an account on Cohere Dashboard. If you're looking for a new technical role at our leading enterprise AI startup, view job openings.