
Today, we’re releasing Command A+ open-source. A mixture-of-experts (MoE) model, Command A+ is an efficient, versatile, and privately deployable LLM built for high-performance agentic tasks with minimal compute overhead.
Born from a year of deploying North with our customers, it surpasses every previous generation in the Command series and unifies their capabilities into a single scalable model.
Now freely available under an Apache 2.0 license, Command A+ advances Cohere’s mission to make sovereign AI a technological reality — giving developers direct access to enterprise-grade agentic capabilities across experimentation, deployment, and production workflows.
Visit Hugging Face to download the weights - available in several near lossless quantizations - and read our implementation guides. For a dedicated, managed inference environment, deploy Command A+ in Model Vault today.
Snapshot
| Model | command-a-plus-05-2026 |
|---|---|
| License | Apache 2.0 |
| Architecture | Sparse / MoE |
| Model size | 218B total; 25B active |
| Context length | 128K input context; 64K max generation |
| Input modalities | Text, image, tool use |
| Output modalities | Text, reasoning, tool use |
| Languages | Supports 48 languages. Full list |
| Optimized for | Reasoning, agentic workflows, RAG, multilingual, multimodal document processing |
| Supported frameworks | vLLM, Transformers |
| Hardware (minimum) | 1× B200 @ W4A4 2× H100s @ W4A4 |
Northwards
For the past year, North — Cohere’s integrated enterprise workspace for building and deploying agentic AI — has been the driving force behind much of our innovation. Through that work, we set out to build a unified model for customers that simplifies deployment, can run locally, and synthesizes capabilities from across the Command family.
The work is already paying off. Read how our customers have been using North to transform their operations.
However, sovereign AI is much bigger than Cohere. Empowering engineers with models that they can run, control, and adapt themselves is the most acute challenge facing this generation of AI.
We’ve optimized Command A+ for practical, developer-focused use, including support for low-bit quantization, efficient inference, and integration across open inference frameworks. AI independence for all.
We can’t wait to see what the community builds.
Command, consolidated
Command A+ outperforms previous Command A models in key dimensions of enterprise workloads, including multimodal understanding, retrieval, long-horizon, and complex reasoning.
| Command A+ | Command A | Command A Reasoning | Command A Vision | Command A Translate | |
|---|---|---|---|---|---|
| Size | 218B A25B | 111B | 111B | 112B | 111B |
| Reasoning | — | — | — | ||
| Multimodal | — | — | — | ||
| Tool use | — | — | |||
| Multilingual | 48 | 23 | 23 | 6 | 23 |
Image 2: comparing the capabilities of Command A+ with other models in the Command A family.
Compared with Command A Reasoning, 𝜏²-Bench Telecom scores improved from 37% to 85%, with agentic coding performance on Terminal-Bench Hard reaching 25% from 3%. Gains were also achieved on non-agentic reasoning, instruction following, and other code generation tasks.
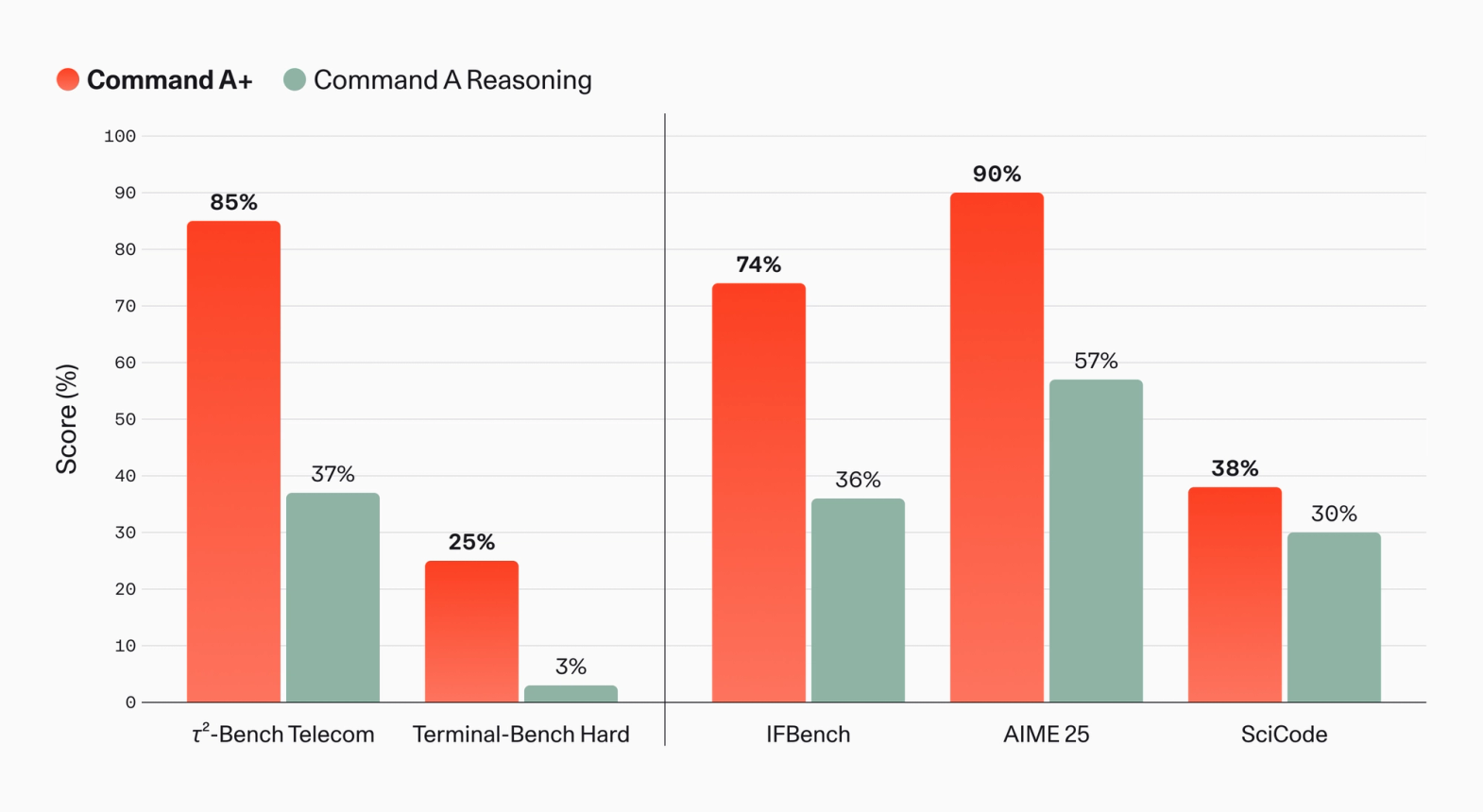
Image 3: Performance for Command A+ and Command A Reasoning on a range of popular open-source benchmarks. See footnote for further details. 1
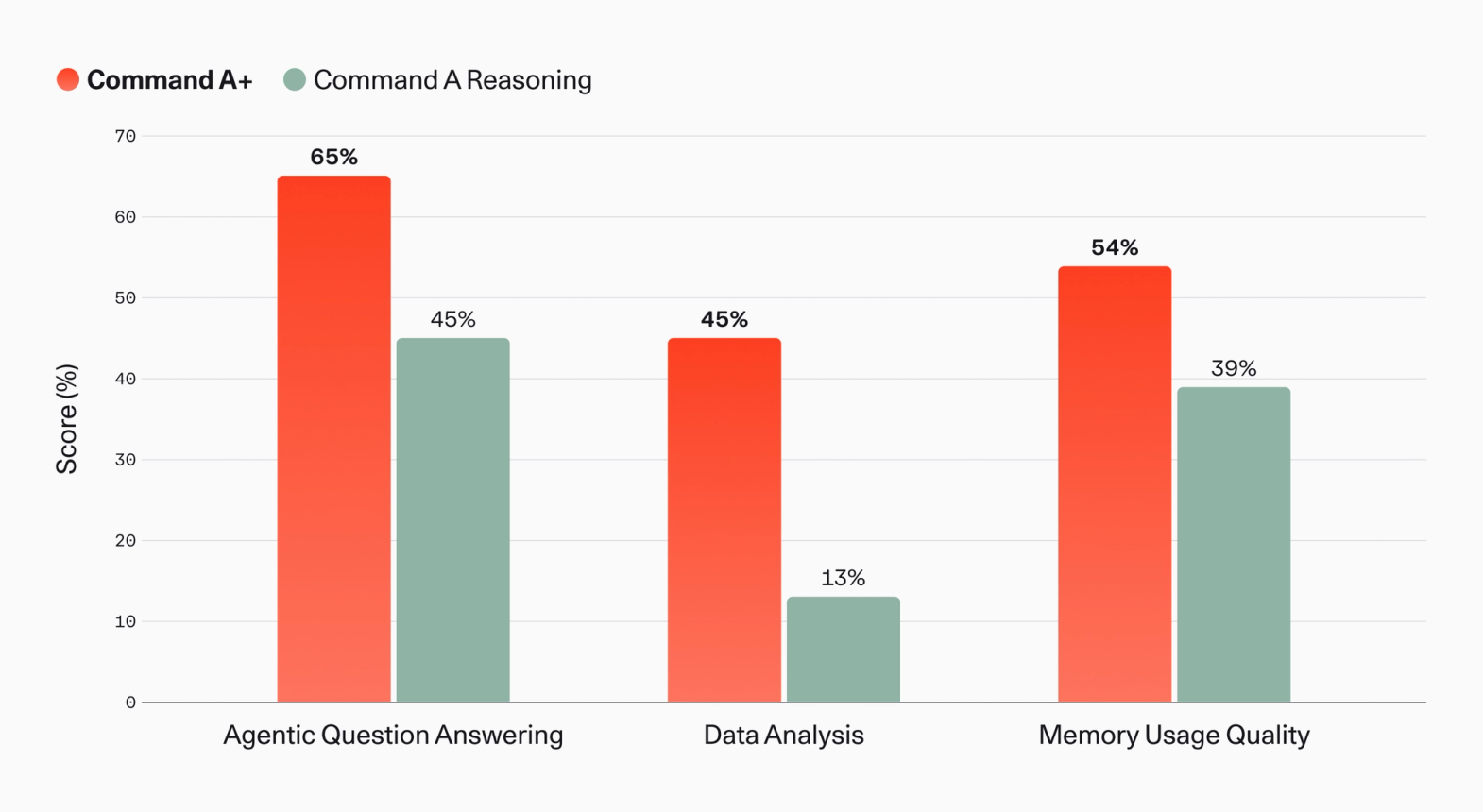
Command A+ performs strongly within North applications, reflecting its original design goals. Agentic Question Answering accuracy and spreadsheet analysis quality improved by 20% and 32% over Command A Reasoning, respectively. Memory performance — testing North’s skill in reasoning across conversations and stored data — scored 54% with Command A+ compared to 39% with Command A Reasoning.
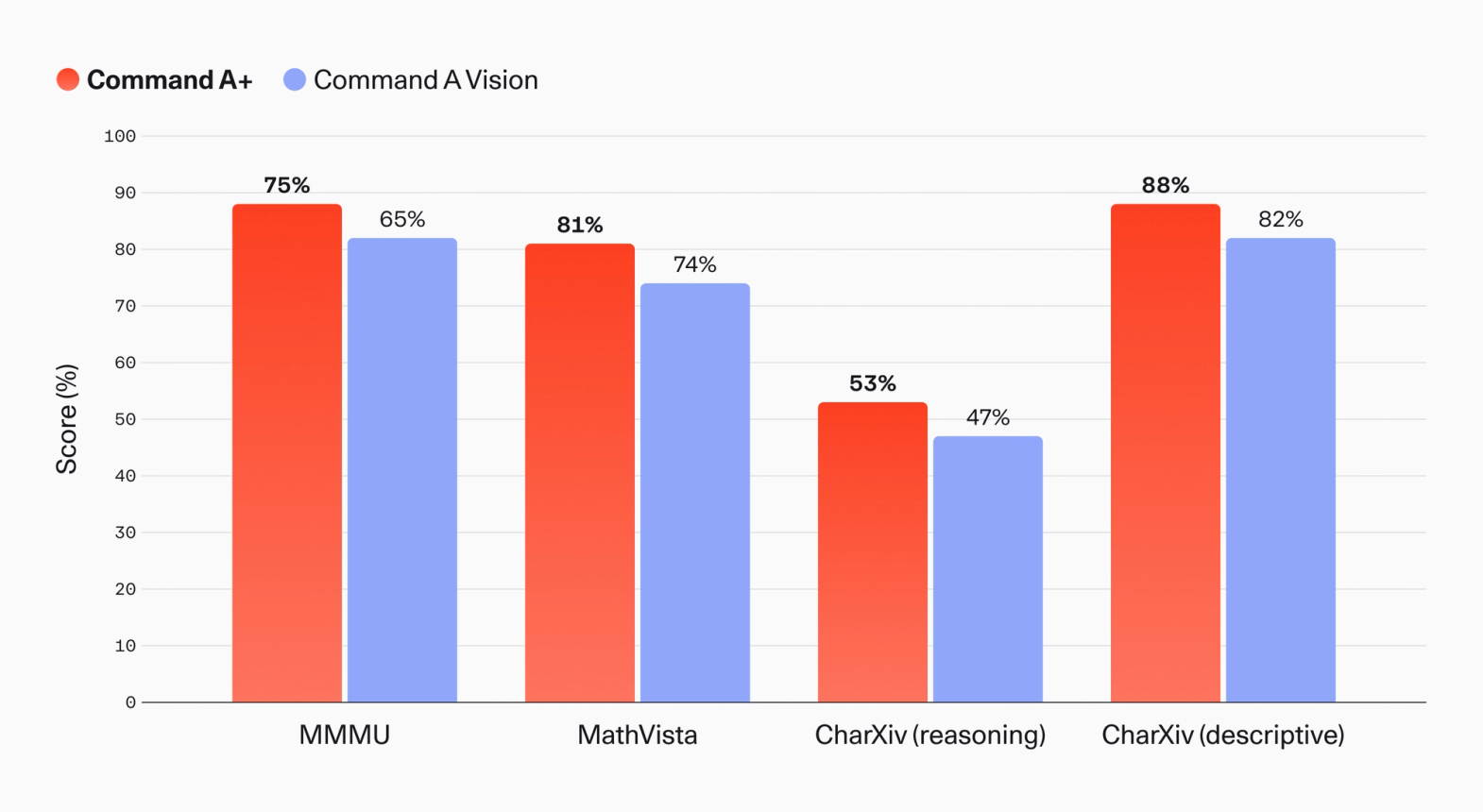
For multimodal understanding and reasoning, Command A+ achieved 63% on MMMU Pro and 75.1% on MMMU, (compared with 65.3% for Command A Vision for the latter). MathVista scores increased from 73.5% to 80.6%, and CharXiv reasoning improved from 46.9% to 52.7%, reflecting broad gains across document understanding tasks.
Command A+ significantly expands multilingual capability, broadening language coverage from 23 to 48 languages and recording gains in machine translation and multilingual reasoning.
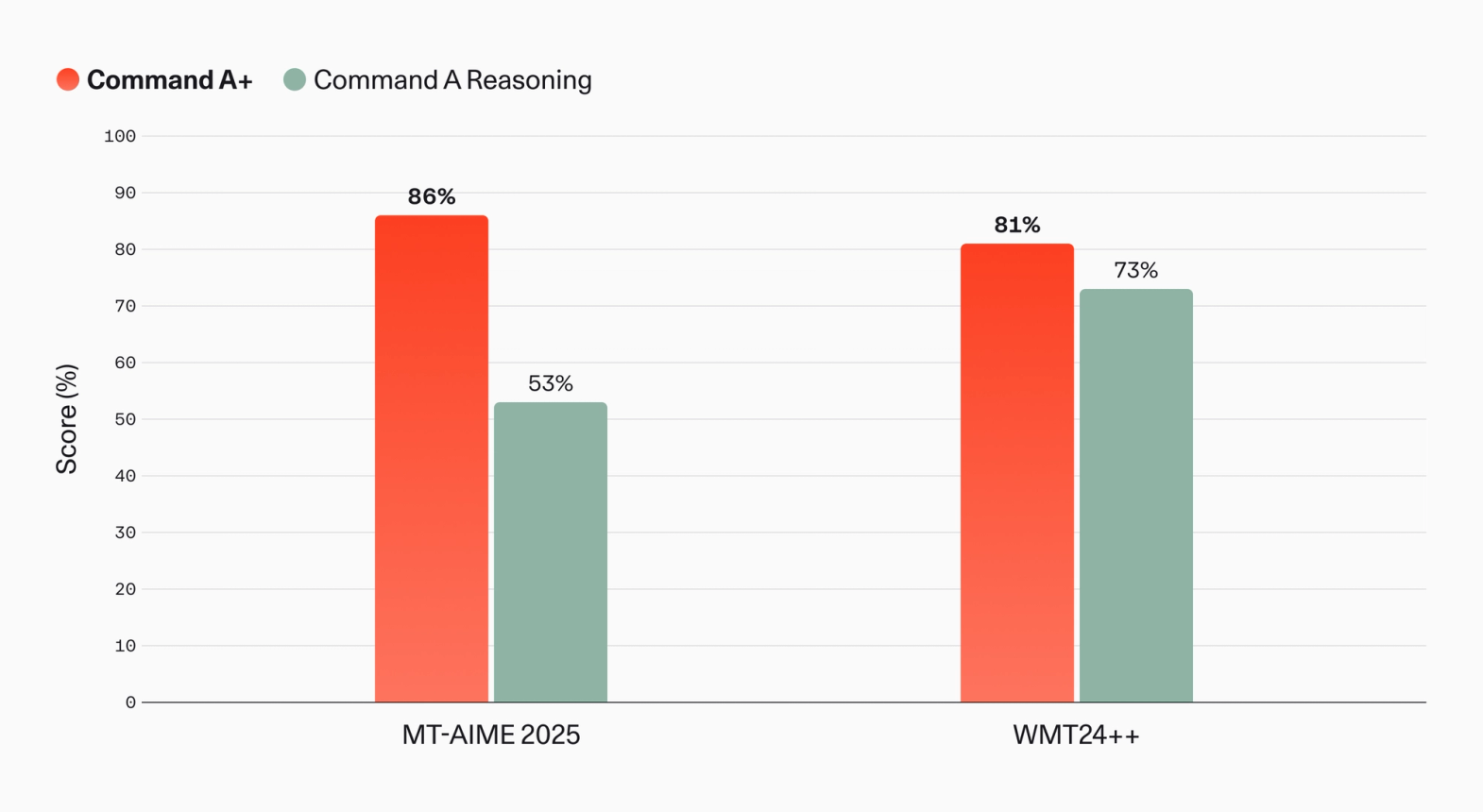
Image 6: comparison of multilingual performance for Command A+ and Command A Reasoning. MT-AIME 2025 is an internal translation of AIME-2025 — an English-language mathematics benchmark — evaluated for Arabic, Japanese, and Korean. WMT24++ is a widely used public benchmark, evaluated here for xCOMETxl. 2
Command A+ achieved a score of 37 on the Artificial Analysis Intelligence Index, outperforming other leading open models, reflecting its strength as a general-purpose model for enterprise agentic workflows [3].
Efficiency at scale
Efficiency is a core constraint in enterprise AI deployment. It determines whether a language model can be deployed practically at scale by shaping the compute, memory, latency, power, and infrastructure required to serve it reliably and cost-effectively.
We engineered Command A+ to be extremely hardware efficient. The model is available today on Hugging Face in 16-bit (BF16), 8-bit (FP8), and 4-bit (W4A4) quantizations, with imperceptible differences in quality. In practice, this enables Command A+ to run on as little as two NVIDIA H100s or a single NVIDIA Blackwell GPU, with virtually no quality degradation.
Command A+ is also our fastest model to date, having 218B total and 25B active parameters compared to Command A Reasoning’s 111B dense architecture. At the same quantization and concurrency levels, it delivers up to 63% higher Output Tokens per Second (TOPS), and reduces Time To First token (TTFT) by up to 17%. The W4A4 quantization contributes an additional 47% increase in speed and a further 13% reduction in latency.
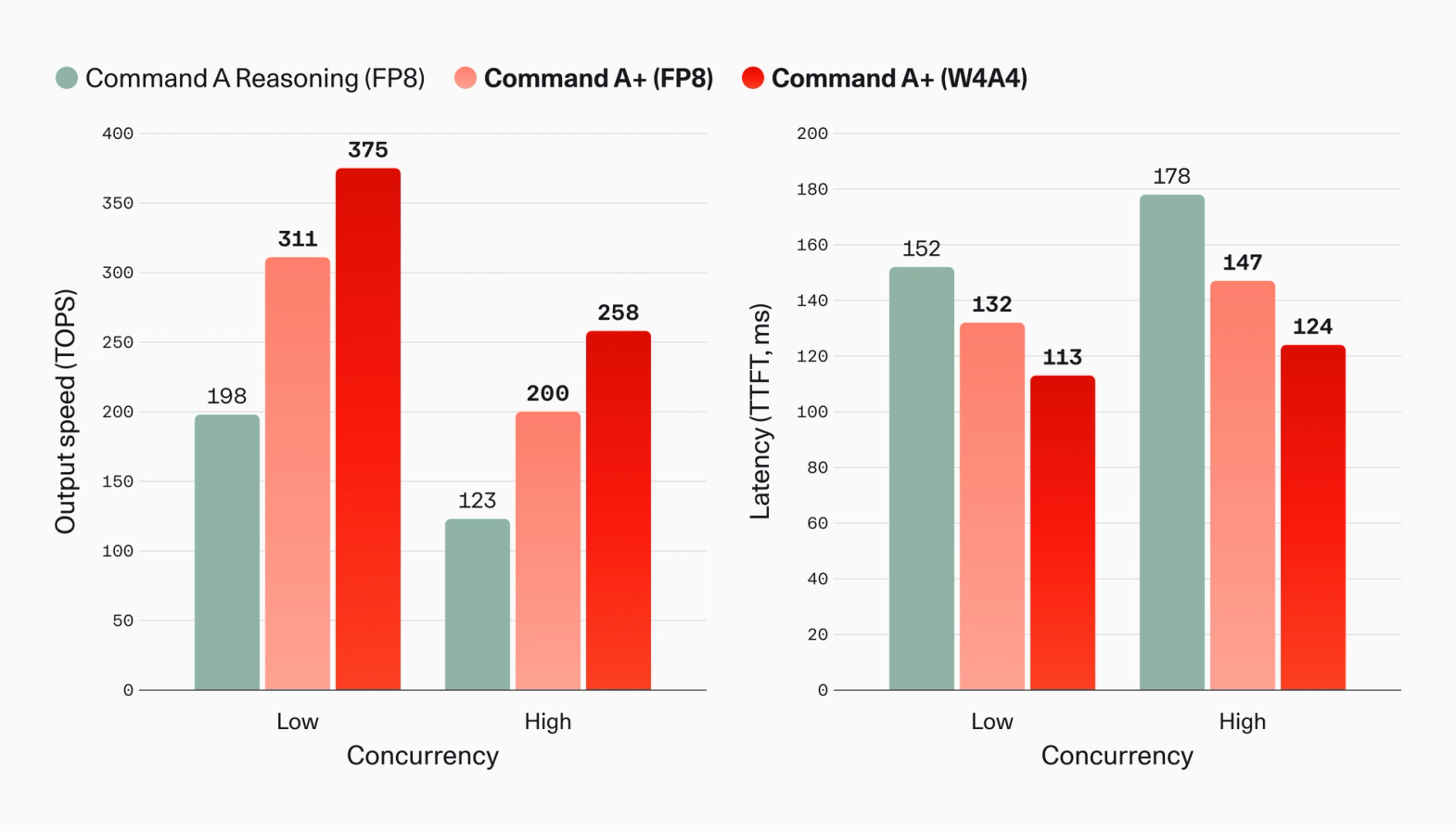
Image 7: Speed and latency of Command A+ compared with Command A Reasoning under different concurrencies and model quantizations. TOPS = tokens per second received while the model is generating tokens (ie. after the first chunk has been received from the API). TTFT = time to first token received, in seconds, after API request sent. 4
We’re also using speculative decoding to accelerate text generation without impacting output quality. We optimized the approach specifically for the model’s MoE architecture, delivering an additional 1.5-1.6x inference speedup for both text and multimodal inputs. Read more about our work here.
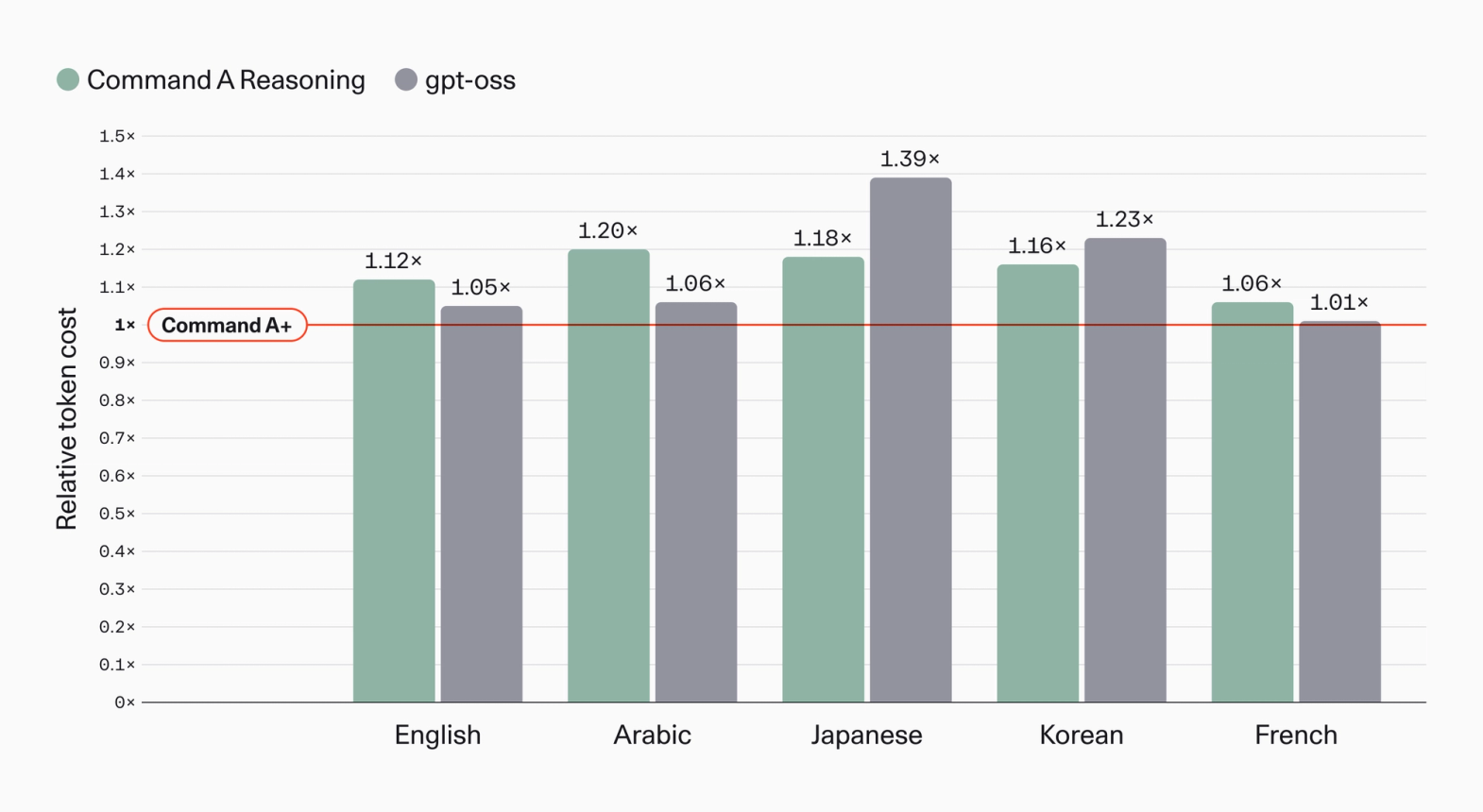
Command A+ is the first model to use our latest tokenizer, delivering substantial compression improvements over its predecessor. Fewer tokens are now required to generate the same response, reducing a major driver of inference cost. Notably, these gains extend to major non-European languages, which are often underrepresented during tokenizer training. Tokenization efficiency improved by 20% for Arabic, 16% for Korean, and 18% for Japanese.
Fujitsu believes Command A+’s mixture-of-experts architecture and strong agentic performance align well with our commitment to deliver innovative, sovereign AI solutions through Takane and the Kozuchi Enterprise AI Factory. We look forward to leveraging its capabilities to accelerate secure, scalable AI adoption for our customers.
Vivek Mahajan
Corporate Executive Officer, Corporate Vice President, CTO, in charge of System Platform
Fujitsu Limited
What’s next?
Progress in sovereign AI today depends on advancing three fronts simultaneously: performance, security, and cost. At Cohere, we are investing across all three — both in our models and in the domain-specific capabilities that power North.
That means improving reasoning, multimodal understanding, and coding performance, while ensuring models remain fit to run entirely within customer environments. The goal is not just stronger benchmarks, but systems that can support enterprise-wide transformation under real operational constraints.
We have already applied this approach across our other model families — including Embed, Rerank, and Transcribe — where we have achieved state-of-the-art performance alongside efficient, cost-aware inference.
Getting started
Command A+ is available today on Hugging Face, as well as through Model Vault. You can also try the model for free on our Space or with a Cohere API key.
Visit our documentation for detailed model specs, deployment guides, and cookbooks to get started.
1 𝜏²-Bench Telecom evaluated using standard settings and user simulation from [Barres et al. 2025]. Terminal-Bench Hard evaluated using Terminus-2 harness following the methodology of Artificial Analysis. AIME 2025 is evaluated on the official 2025 set of 30 questions, each question being repeated 10 times. The score is the pass@1 over this 300 sample dataset. IFBench is for single turn, loose evaluation mode and the score reported corresponds to prompt accuracy over 1470 samples corresponding to 294 unique prompts repeated five times. Scicode evaluated using 65 test problems which includes 288 subproblems. We prompt each subproblem with the 'scientist-annotated background' following the methodology of Artificial Analysis.
2 MT-AIME was translated from English using Command A Translate. WMT24++ score is the average of 50 varieties: all supported languages, including ar_EG, ar_SA, pt_BR, pt_PT, zh_CN, zh_TW from the original WMT24++ test set. Serbian is evaluated with an internal transliteration to the Cyrillic script. Irish and Maltese are internally-created translations of WMT24++.
3 To train the Command A+ model efficiently at scale, we leveraged NVIDIA’s CUDA-X ecosystem (CUTLASS, cuBLAS, TE and NCCL) for high-performance computation, kernel optimization, and multi-GPU communication.
4 All models were measured on a single NVIDIA HGX B200 node (8 x GPUs), using vLLM with tensor parallelism (TP=8), against LiveCodeBench. Prompts were ~3K tokens with an 8K max output length.